I have a repeating-list-datafield with a list of entries of unknown length (or length n). The concept is #party, and I have the datafield #party^is-a-shareholder as a true/false-repeating-list.
If I display the list, using @list(#party^is-a-shareholder), I get (for example, depending on the data):
“Parties X hereinafter referred to as “Shareholders”.
Because the Parties are numberd sequentially, X needs to refer to the repeating-list-datafield index of all entries set to “true”, and skip any entry set to “false”. Ideally, using the above example data, I want to display:
*1. Parties 1 and 3 hereinafter referred to as “Shareholders”*
Parties 1 through 4 and 7 hereinafter referred to as “Shareholders”*
Parties 1 through 3 and 7 through 10 hereinafter referred to as “Shareholders”*
I have tried using @count, turning the list into a string with @str and using @regex or working with a @for loop, without success. I am sure there is a way to achieve this.
I would greatly appreciate some ideas here, as this really has me stumped.
What you are trying to achieve is not exactly advanced when looking at it from a legal perspective (such paragraphs are produced every day), but from a technical perspective this is actually quite advanced.
Clause9 offers several advanced tools that solve several of those advanced use cases, but you should be aware that there are limits. In fact, these kinds of challanges are usually solved with a traditional general-purpose programming language. We also embed one within the software (Clojure), and you can actually use it to compose paragraphs with even the weirdest logic you can think of, but it’s something you want to avoid, due to the complexity involved and the difficulty to maintain.
So let’s try to use the standard (although advanced) tools in Clause 9.
Have a look at the way I solved it in the screenshot below (I use slightly different concept-names & fields, but ignore that).
Make sure to read the page about for-loops — I assume you already did, but probably that’s a good starting point for a future reader.
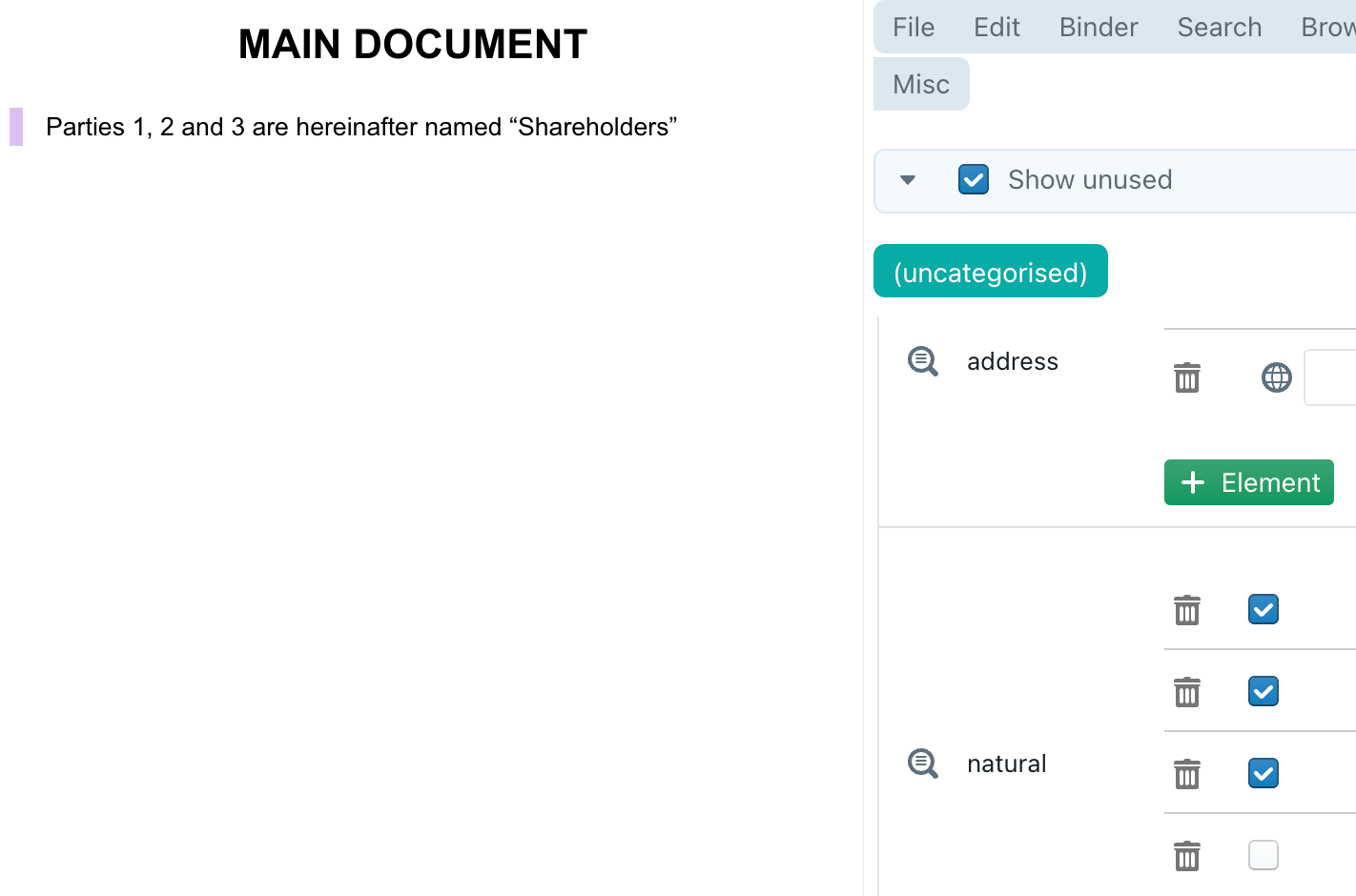
Let’s suppose there are 4 parties in total, with party 1 and party 4 being natural persons.
The ALL-INDICES loops over each of the 4 parties, and then for each party invokes the SNIP. Notice that I’m using @for-calc and not @for, because @for-calc returns a number (instead of a piece of text), which is easier to work with later on, for comparison reasons.
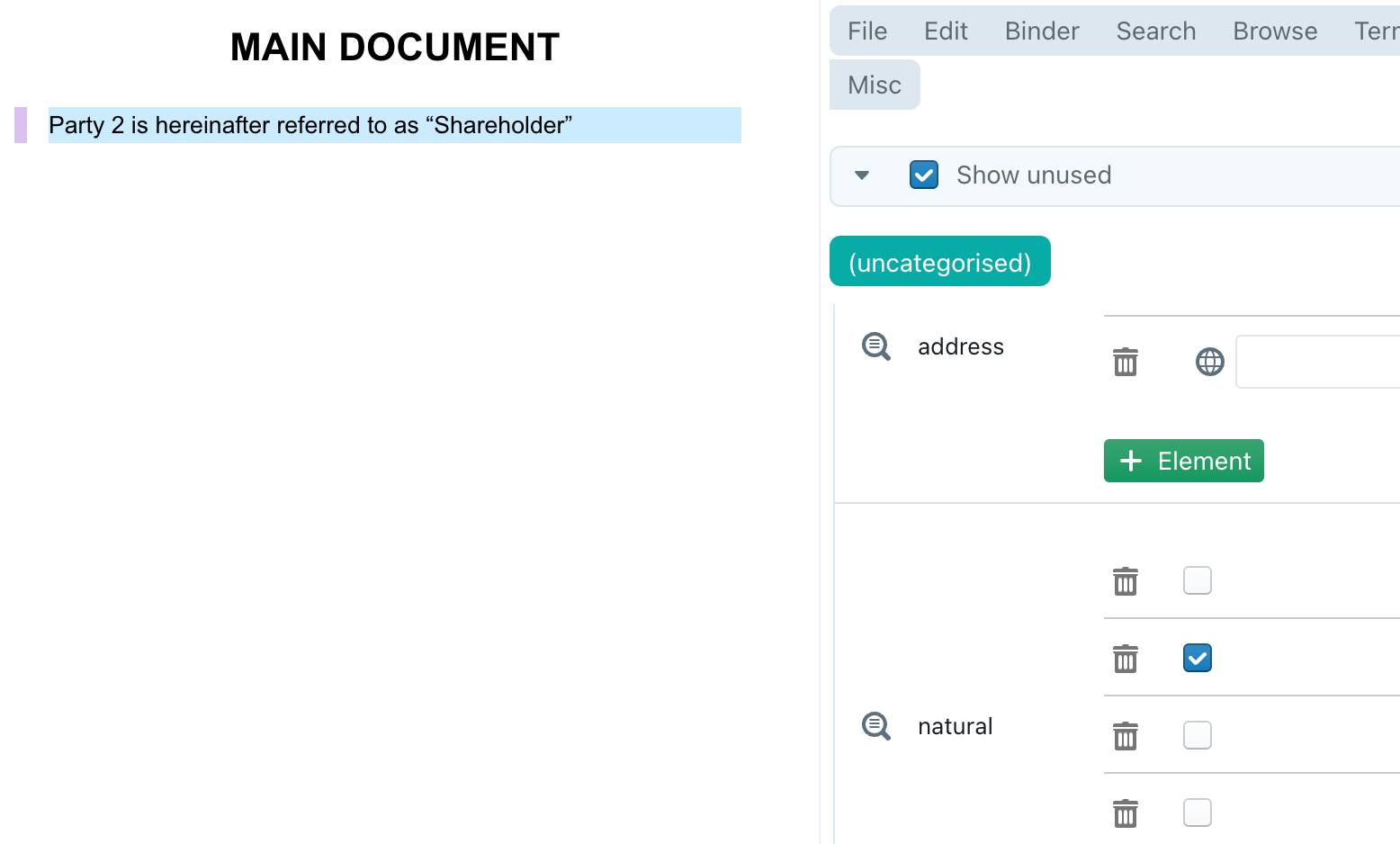
The SNIP looks at a party and then checks whether it is a natural person, by using @get into the repeating list #cparty^natural, with the current index (1, 2, 3 or 4).
I’m using @when to check the condition, because that returns either the index as a natural number (?INDEX, which is a number), or nothing if the condition is not met. If I would have used something like {#cparty^natural: ?INDEX}, then that would result into a piece of text (everything after the colon will ultimately become text, or even text with formatting inside), which is more difficult to compare. Hence the reason to use @when, because it does not convert ?INDEX into a piece of text.
ALL-INDICES will thus result in a list that contains four elements: 1, nothing, nothing and 4.
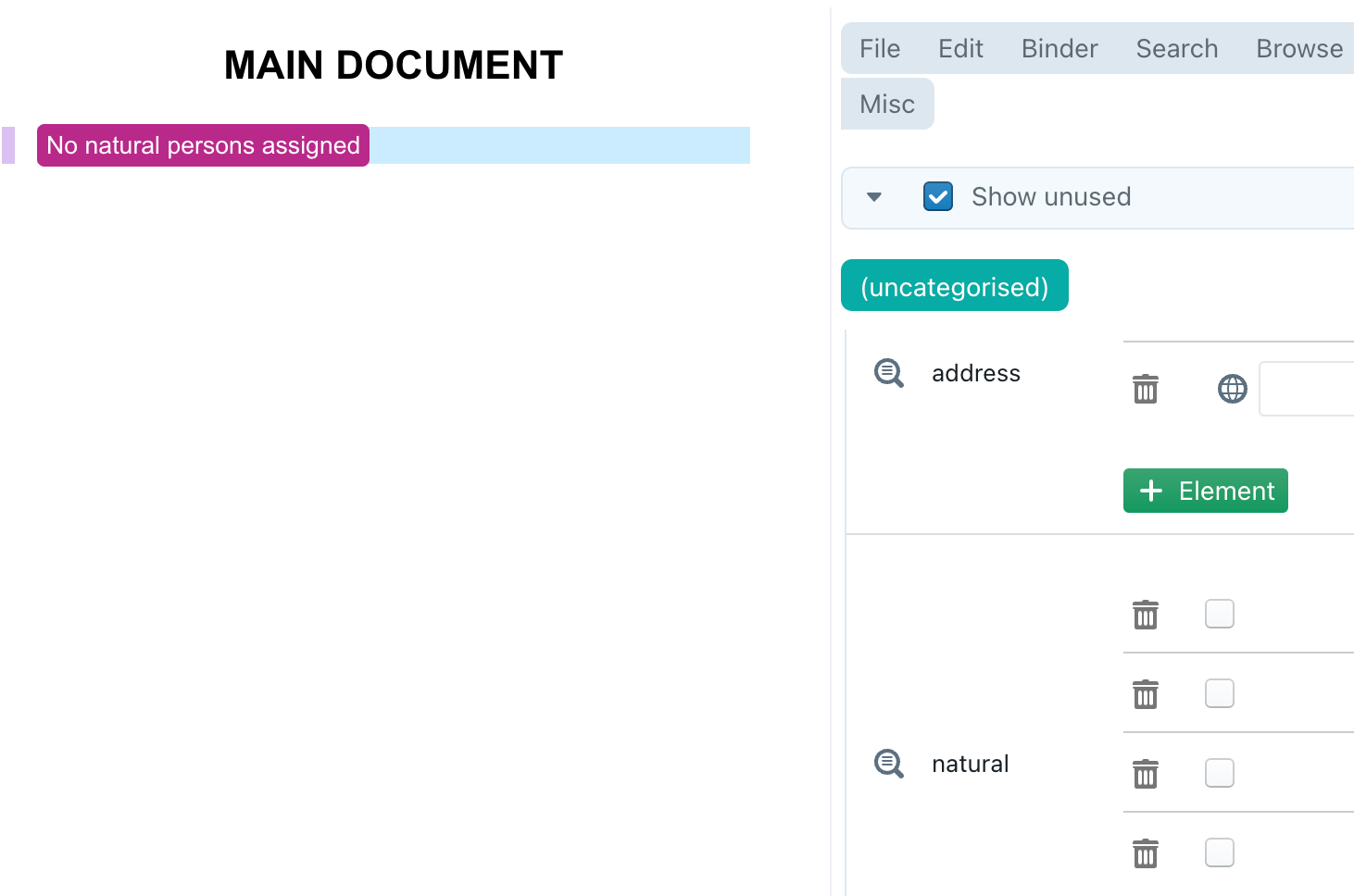
FILTERED-INDICES then takes the ALL-INDICES and removes the two “nothing” elements, by comparing with “undefined” (i.e., nothing). It thus results in a list with just two elements: 1 and 4.
In the actual paragraph, I then do a check on the number of elements within FILTERED-INDICES:
if that number of elements is zero, then I give an ugly warning in red (perhaps you instead want to generate nothing in that scenario, instead of an ugly warning)
if that number of elements is exactly one, I produce a text referring to that party in singular
if the number of elements is more than one, I produce a text referring to the parties in plural, and nicely concatenating the results with @enumerate-and
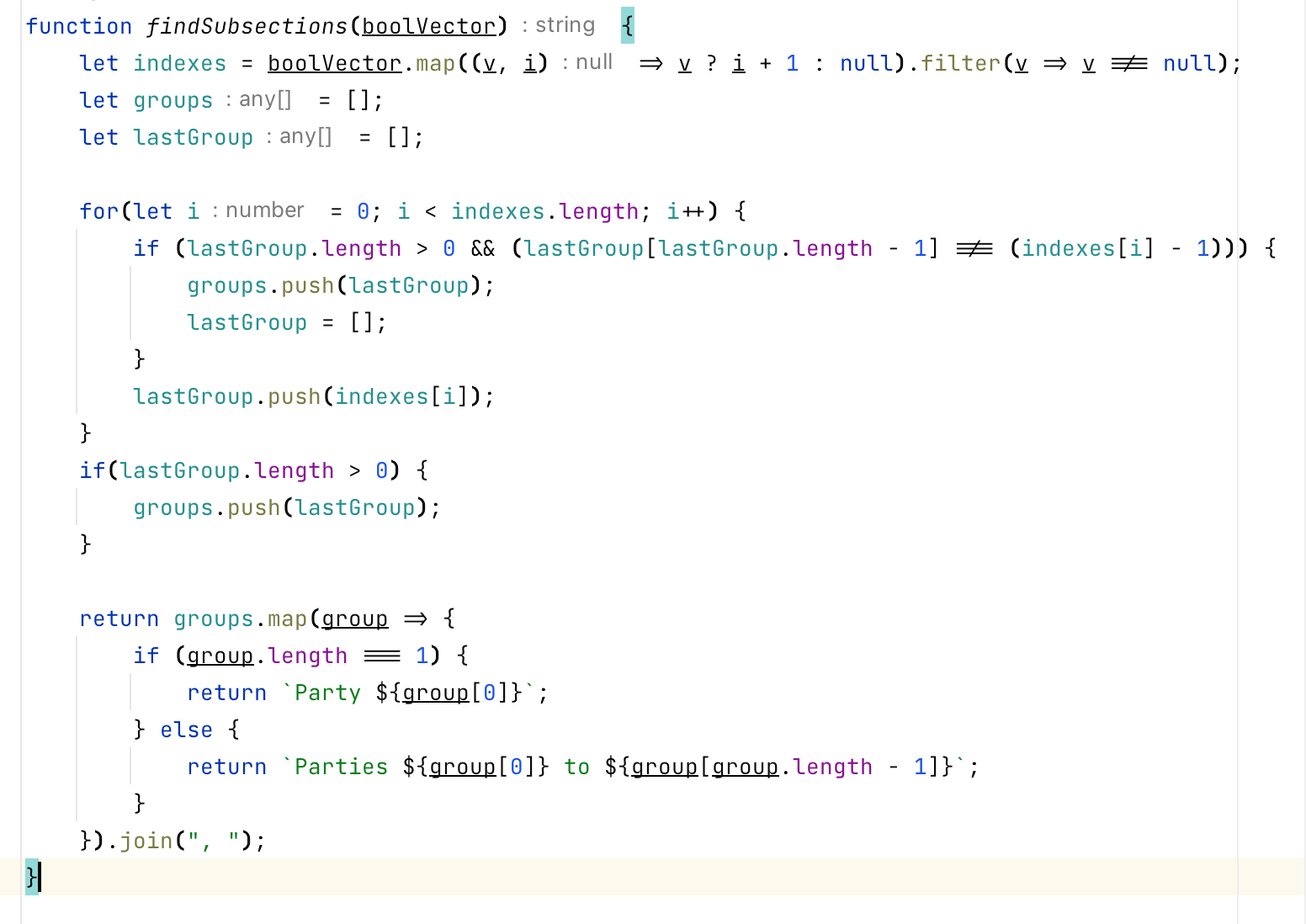
This works well, except for one scenario: your example with “Parties 1 through 3 and 7 through 10”, i.e. where you want to group contiguous parties together. This cannot be resolved with simple for-loops, you really need a general-purpose programming language — and even then it’s not exactly super simple.
We use Clojure as an embedded programming language, but this is what it could roughly look like in Javascript (quickly done with the help of GPT-4), to illustrate the level of complexity.
We could envisage creating a new special function that performs these kinds of “contiguous number grouping” things (i.e., where the complex programming stuff is prepared by the ClauseBase-team and “hidden” behind an easier-to-use special function), but I suppose the use case for it is fairly limited among our users, so let’s leave that for the future.
Maarten, your solution has been working very well within clauses and documents! I am continuing this thread as I have a related question:
I am attempting to change the concept label based on the amount of true/false values of a specific row of a repeating list datafield. Using the above example, if only a single entry in my repeating-list-datafield is set to “true”, my #shareholder concept should use the Singular label, otherwise the Plural one.
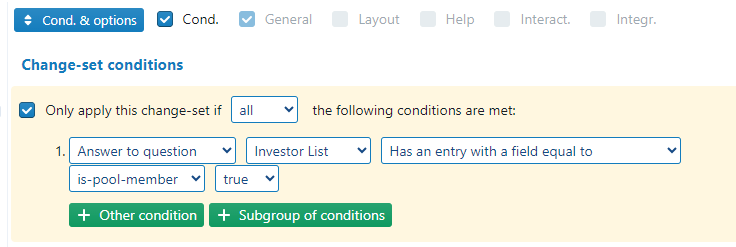
Using the Q&A Change-set conditions, I have not been able to achieve this. Whilst I can set Number fields to “greater than one”; the condition for true/false only checks if there are any “true” settings, not how many:
As such, I have not been able to distinguish between “one” or “more” using this Change-set.
As a quick fix, I resorted to including the above logic within every clause that uses any party-related concept - essentially ignoring that concept labels even exist. This makes even short clauses rather long and complex, and I fear for both long-term maintenance and scaling.
I have attempted to create a Q&A Change-set condition using Expressions , but have not gotten this working:
Is it possible that Snippets are not recognized within Q&A Expressions?
Ideally, I want to avoid asking the User "Do you have One or More Shareholders/Founders/Holding Companies/Pool Members etc., if that information could already be gained from the entries into a repeating-list datafield. I also fear user error (selecting “Singular”, then adding another Party and forgetting to change it).
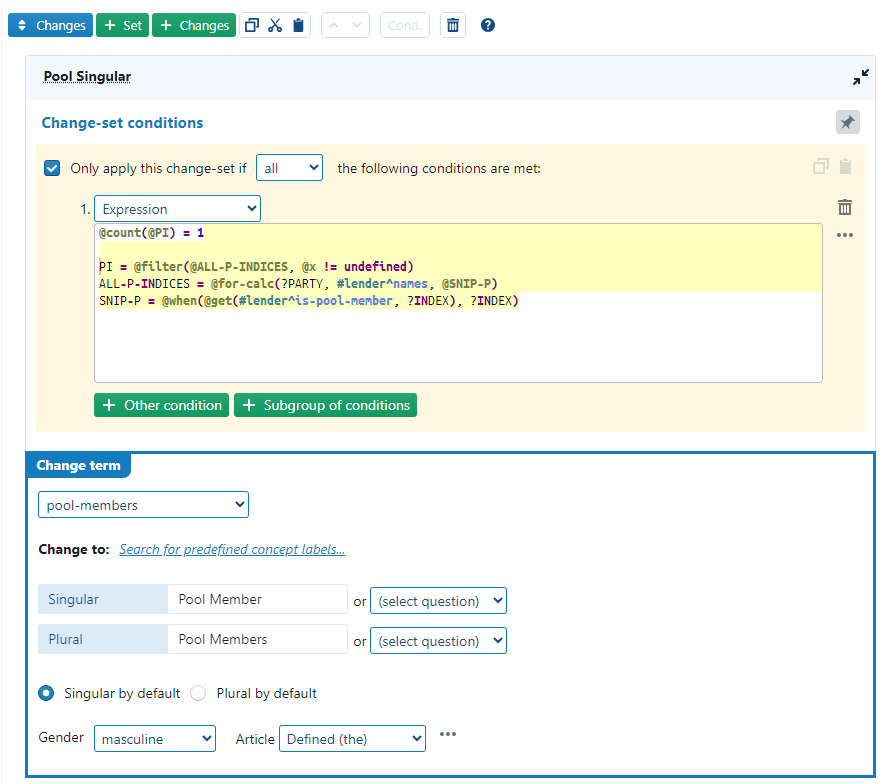
You are right that Snippets are not recognised within Q&A Expressions, they only work within real clauses. Technically, snippets are actually immediately “integrated” within the clause during a setup phase, i.e. when software starts using the clause. So something like
@count(@PI) = 1
PI = @filter(xyz)
is immediately changed into:
@count(@filter(xyz)) = 1
For the Q&A expressions, there is no such setup-phase, and that’s why the software highlights this as an error. The solution is therefore that you do the integration yourself, so it would
This will be quite ugly, but that ugliness is also kind of a sign that you’re reaching the boundaries of what the system is intended to do. Congratulations that you reached this boundary
If you want to go even further, you’ll have to resort to the embedded programming language.
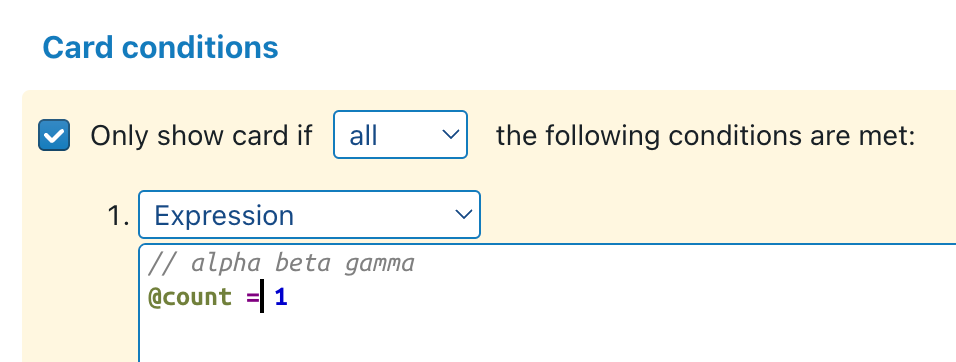
Maybe a small hint: to mitige the ugliness a little bit, I would advise you to put the original 4 lines after double slashes, so they are preserved as comments, similar to the “alpha beta gamma” in the screenshot below. This allows your future self to hopefully understand where your huge expression comes from.
I have tried your proposed solution and can’t get it to work.
However, your comments have helped me concluded that that way madness lies, in terms of maintenance, readability, and potentially even performance. I will end up changing the system.